- Special Issue 07 [퓨리오사에이아이] 혁신의 주역, 퓨리오사에이아이
2017년 창립한 ㈜퓨리오사에이아이는 AI 하드웨어 분야에서 주목받는 대한민국의 팹리스(Fabless)스타트업이다. 퓨리오사에이아이는 데이터센터를 위한 저전력·고성능 NPU(Neural Processing Unit)를 설계하며, 이를 기반으로 한 카드 및 서버를 제작·판매하고 있다. AI 기술의 발전과 함께 시장의 요구에 맞춘 혁신적인 제품을 통해 글로벌 시장에 도전장을 던진 퓨리오사에이아이는 대한민국 기술력의 새로운 장을 열어가고 있다.
AI 하드웨어 시장의 핵심 동향
AI 기술이 전 세계를 휩쓸고 있는 가운데, 이 분야에가장 큰 수익을 거둔 회사는 어디일까? 많은 이들이 OpenAI의 ChatGPT를 떠올릴 것이다. 출시 2개월 만에 월간 사용자 1억 명을 돌파하고 현재는 2억 명 이상이 사용 중인 ChatGPT는 AI 기술의 잠재력을 보여준 사례로 평가받는다. 그러나 놀랍게도 OpenAI는 2022년에 약 7천억 원의 손실을 기록했다. ChatGPT 서비스를 운영하기 위해 매일 약 20억 원의 인프라 비용을 소모했기 때문이다.
이처럼 AI 서비스 운영에는 대규모 데이터와 연산을 처리할 수 있는 하드웨어가 필수적이다. 현재 대부분의 AI 연산은 NVIDIA의 GPU에서 이루어진다. 이에 따라 NVIDIA는 엄청난 성장을 기록해 오고 있으며, 2024년 기준 시가총액이 약 3.35조 달러(약 4,700조 원)에 이른다. 결국 AI 서비스로 가장 큰 수혜를 입는 기업은 직접적인 AI 제공 기업이 아닌, 이들을 뒷받침하는 하드웨어 제조기업이라고 할 수 있다.
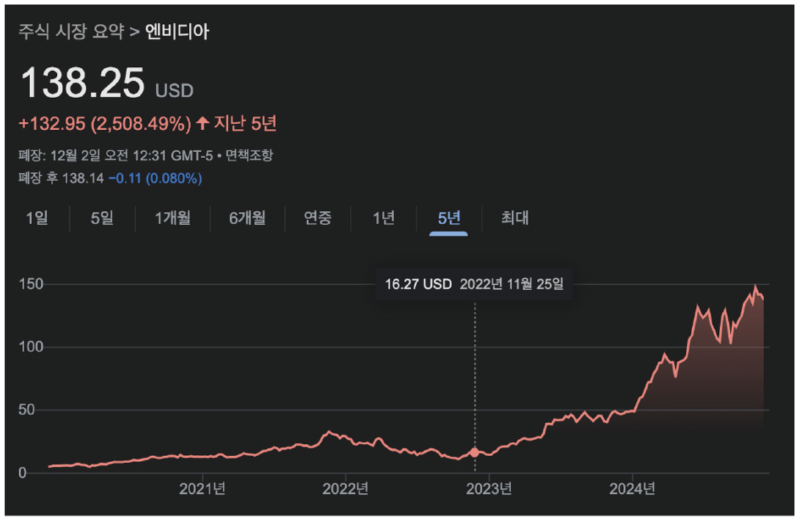
- 엔비디아의 주가 그래프는 ChatGPT를 출시한 2022년 11월부터 꾸준한 우상향을 보임
NVIDIA에 도전하는 대한민국 팹리스 스타트업
퓨리오사에이아이는 2016년 알파고와 이세돌 간 대국에서 영감을 받아 이듬해인 2017년에 설립되었다. NVIDIA의 GPU를 대체할 수 있는 AI 추론 가속 칩 NPU를 개발하는 것을 목표로 시작한 퓨리오사에이아이는 글로벌 AI 하드웨어 시장에서 경쟁력을 확보하며 성장하고 있다.
그림2 퓨리오사에이아이 1세대 칩 WARBOY와 2세대 칩 RNGD 개발 히스토리

회사 창립과 동시에 설계가 시작된 1세대 칩 WARBOY는 그 당시 가장 각광받던 시각 인공 지능 모델(Vision AI Model)의 주류인 CNN(Convolutional Neural Network) 가속에 특화된 NPU이다. WARBOY는 2021년 개발이 완료되고 2022년 말 양산되어, 이를 국내의 클라우드 업체 및 시각 인공지능 서비스 회사가 사용하고 있다.
퓨리오사에이아이는 2021년에 등장한 GPT3를 보고, 앞으로 인공지능은 LLM(Large Language Model)이 주도할 것으로 예상했다. 따라서 2022년에 2세대 칩인 RNGD(레니게이드)의 설계를 시작할 때 HBM(High Bandwidth Memory)을 선택했다. 대부분이 HBM3와 같은 고성능의 메모리는 추론 전용 칩에는 오버 스펙이라고 우려했지만, 그럼에도 퓨리오사에이아이는 과감히 HBM3를 선택했다.
이후 2년간의 설계, 개발, 제조 과정에서 퓨리오사에이아이의 모든 열정과 역량을 담은 RNGD 칩이 2024년 5월 처음 신사 오피스에 도착했다. HW와 SW 엔지니어가 2개월 동안 크런치 모드로 노력한 결과, 2024년 7월에는 GPT-J를 RNGD에서 안정적인 성능으로 데모하는 데 성공했다. 9월부터는 몇몇 중요 고객과 PoC(Proof of Concept)를 진행 중이다. 2세대 칩 RNGD는 한 대의 서버에 카드 8장을 장착하여 ChatGPT 급의 서비스를 수행할 수 있는 고성능 칩으로, LLM을 활용한 여러 애플리케이션에서 사용할 수 있다.

기술 혁신을 이끄는 인재 확보 전략
퓨리오사에이아이는 2017년 백준호 대표, 김한준 CTO, 구형일 CAO(Chief Algorithm Officer) 세 명이 설립했다. 아키텍처, 하드웨어, AI 알고리즘의 전문가가 모였지만, AI 반도체를 만들 때 필수적인 컴파일러 전문가가 없었다. 따라서 백준호 대표는 전 세계 최고 컴파일러 전문가를 어디에서 찾을 수 있는지 주변에 문의하다가, PLDI(Programming Language Design and Implementation) 학회를 알게 되었다.
PLDI는 프로그래밍 언어와 컴파일러 분야의 명실공히 세계 최고의 학회다. 백준호 대표는 혈혈단신으로 아무 정보도 없이 스페인 바르셀로나에서 열린 PLDI 학회에 참석하기로 결단했다. 스페인에서 학회 장소를 찾아 헤매게 되었는데, 똑같이 길을 헤매던 한 사람을 만나 무사히 학회장에 도착했다. 그제야 통성명한 그 사람은 컴파일러 연구로 최고 논문상(Distinguished Paper Award)을 받은 서울대 허충길 교수였다. 이로써 백준호 대표는 대한민국의 컴파일러 연구 수준이 세계적인 수준이라는 것을 알고 자신감을 얻게 되었다. 이후에는 허충길 교수의 제자인 강지훈 박사가 초창기 퓨리오사에이아이 합류하여, 컴파일러팀 리더로 재직 중인 구본철 박사와 함께 컴파일러 설계 및 구현을 했다. 강지훈 박사는 현재 카이스트 전산학과 교수로 재직 중이다.
AI 반도체 설계에는 AI 알고리즘, 아키텍처, HW, SW 등 모든 분야의 역량이 필요하다. 각 분야는 또 여러 개의 세부 분야로 나눠지는데, 그 세부 분야마다 전문가가 갖춰져야만 AI 반도체 제품을 만들 수 있다. 다행히 퓨리오사에이아이는 회사가 필요로 하는 순간마다 때마침 훌륭한 전문가들이 합류해 왔다. 현재 퓨리오사에이아이에는 삼성전자, 쿠팡, 구글, 아마존, Meta 등에서 이직한 다양한 경력의 엔지니어들이 일하고 있다.
SW & HW 통합 설계로 경쟁력 확보
인공지능 반도체는 뛰어난 HW뿐 아니라, 사용자가 원하는 AI 모델을 칩에 최적화해 주는 SW 스택까지 통합 지원해야 한다. 전 세계적으로 여러 NPU 업체가 등장했으나 아직 엔비디아의 독주를 막지 못하는 가장 큰 원인으로, 이러한 SW 지원의 한계를 꼽을 수 있다.
엔비디아는 CUDA(Compute Unified Device Architecture) 기술로 오랜 기간 SW 생태계를 구축해 왔다. 이를 통해 사용자는 원하는 다양한 AI 모델을 GPU에서 수행할 수 있었다. 그러나 대부분의 NPU 업체들은 GPU 대비 고효율의 하드웨어를 만드는 데는 성공했을지라도, GPU처럼 다양한 AI 모델을 동작시키기 위한 유연한 SW의 지원은 부족했다.
이러한 문제는 HW 팀이 HW를 설계하는 방식을 바꿔 단독으로 해결하기는 어렵다. 이 부분이 대기업에서도 NPU와 같은 새로운 영역의 AI 하드웨어 가속기를 만들지 못하는 이유라고 할 수 있다. HW 팀이 먼저 설계하고 결정하여 우선 HW를 만들고, 나중에 SW 팀이 만들어진 HW가 구동하도록 작업하는 방식은 비효율적이다. 또한 컴파일러가 해야 하는 일의 복잡도가 너무 커져서 다양한 AI 모델을 컴파일하는 데 실패하거나, 너무 많은 엔지니어링 리소스가 필요해지기도 한다. 여러 글로벌 NPU 회사들이 동일한 이유로 많은 어려움을 겪었다.
반면, 퓨리오사에이아이에서는 칩을 설계할 때 HW 아키텍처팀과 SW 컴파일러팀이 함께 작업한다. 워룸(war-room)이라고 부르는 공간에 두 팀이 함께 모여, 시뮬레이션 결과를 바탕으로 HW 최적화, SW 최적화를 동시에 진행한다. 이 과정에서 서로의 영역에 필요한 기능을 추가하기도 하고, 개선하기도 한다. 또한 두 팀은 다양한 AI 모델을 지원하기 위해 최적의 HW 추상화 수준(abstraction level)을 결정한다. 가속의 대상인 AI 워크로드(workload)의 특성을 분석하고, 어떤 연산들을 가속하는 것이 가장 중요할지 결정한다. 특히 그 연산들을 구성할 수 있는 근본 연산(primitive operation)이 무엇일지를 정의하는데, 컴파일러팀은 다양한 AI 모델을 어떻게 근본 연산들로 구성할지와 어떠한 방식으로 HW에 맵핑하여 최적화할지를 연구한다.
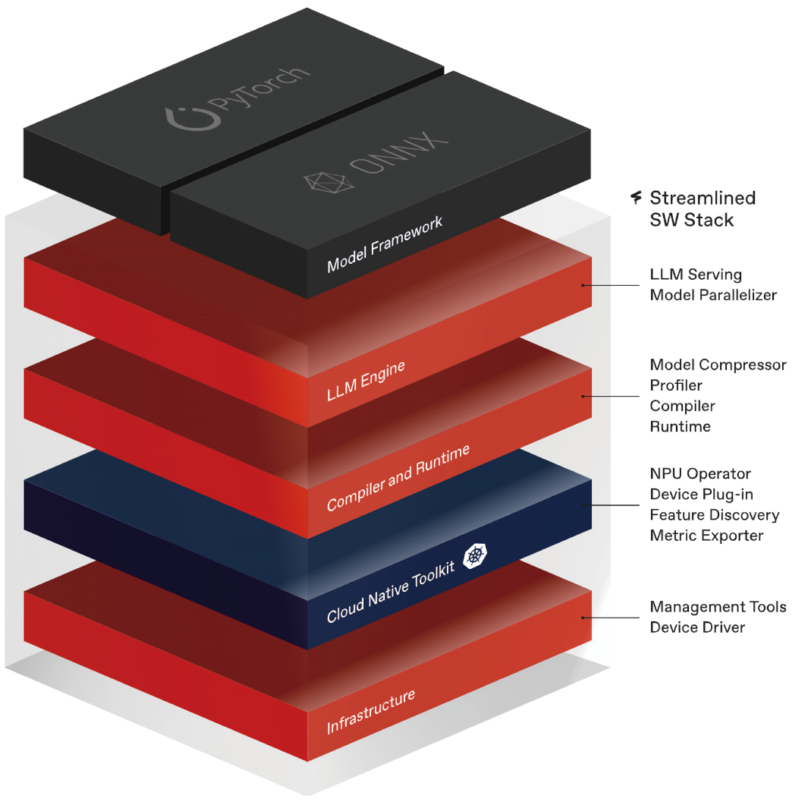
퓨리오사에이아이는 다양한 AI 모델을 최적으로 지원할 수 있도록 일반적인 컴파일러를 추구한다. 다양한 AI 모델을 분석하여 자동으로 최적의 컴파일 전략을 찾아내는 ‘컴파일러 SW’를 만드는 방식이다. 엔비디아의 최적화 방식과는 다르다. 많은 엔지니어가 다양한 워크로드에 따라 GPU가 높은 성능을 구현할 수 있도록 다양한 CUDA 커널 코드를 직접 개발해 놓고, 라이브러리를 조합하여 사용한다. 한편, 퓨리오사에이아이는 엔비디아보다 더 적은 엔지니어 인력으로 다양한 AI 모델들을 지원하기 위해 일반적인 컴파일러 개발 전략을 택했다. 초기에는 최적화 성능이 상대적으로 부족한 듯 보여도, 전체 AI 모델 최적화 관점에서는 일반적인 컴파일러의 개발이 결국 더 속도를 낼 것으로 예상한다.
글로벌 시장을 향한 도약
퓨리오사에이아이를 포함하여 Graphcore, Groq, Cerebras, Sambanova, Tenstorrent 등 전 세계의 다양한 NPU 회사들은 이제 가치를 실제 매출로 증명할 때이다. 지금까지 투자 대비 유의미한 매출을 보여준 NPU 회사는 없다. 한편 퓨리오사에이아이의 2세대 칩 RNGD는 LLM 모델을 활용한 서비스가 많아지고 사용자 수가 폭발적으로 증가할 시점에 맞추어 출시되었다. 퓨리오사에이아이는 2025년부터 RNGD의 대량 생산을 통해, 세계 무대에서 매출 숫자로도 대한민국의 기술력을 입증하는 글로벌 NPU 선도 기업으로 자리매김할 계획이다.
퓨리오사에이아이는 앞으로도 기술 혁신과 인재확보를 통해 AI 반도체 시장의 판도를 바꾸는 도전을 이어갈 것이다. “글로벌 시장에서 성공하는 대한민국 팹리스 스타트업”이라는 비전이 현실로 다가오고 있다.

- Vol.469
25년 01/02월호




